Hello!
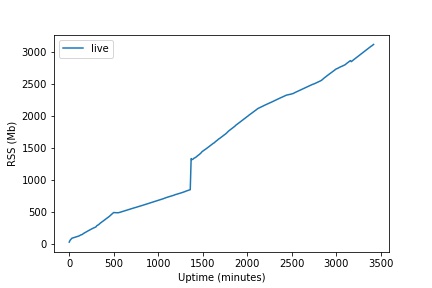
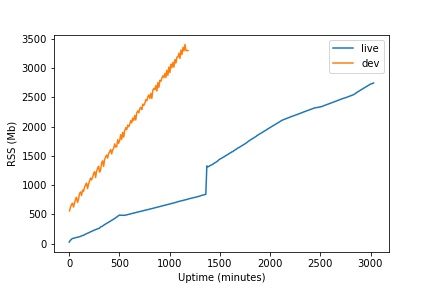
Unfortunately it seems we are still experiencing a linear memory leak. See below a uptime (minutes) vs RSS (Mb) chart for our live and development servers.
Notes:
- On dev we ran the equivalent of the testsuite’s ‘stress_memory’ function every 10 seconds.
- Neither live nor dev have any compiler options on.
- The spike on live was us worrying maybe we had not properly switched the 2019 branch, and verifying that reclaim_objects() was also freeing memory by doing the equivalent of ‘stress_memory’. Yay, it did.
- I was saving RSS data using a 10 minute cron job, which is why dev is ‘noisy’.
I wanted to investigate so we loaded up the testsuite using: debug, debugmalloc, debugmalloc_extensions and package_develop and I ran it for awhile doing stress_memory every 10 seconds. I changed it to i<1000 instead of i<100. This is that running for a few hours:
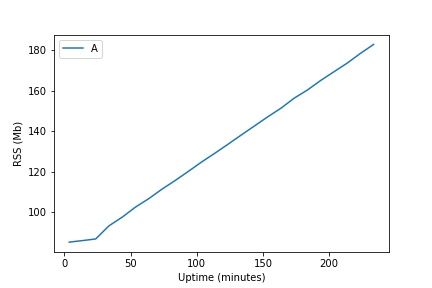
Note that there is a fairly long period until the memory leak overcomes the initial jump in RSS caused by populate_mixed(1). I believe this initial reservation ‘jump’ is why running stress_memory makes it look like Max RSS is stable after a fresh testsuite boot. At i<100 it would take roughly 5 hours to catch up.
To test this I rebooted and replaced:
HOLDER->populate_mixed(1);
with
load_object( HOLDER );
so that stress_memory now looks like:
#define HOLDER "/clone/memory_holder"
void report() {
write("After: \n" + mud_status(0) + "\n");
}
int main(string arg) {
write("Before: \n" + mud_status(0) + "\n");
write("populate Map... \n\n");
for(int i=0; i<1000; i++) {
//HOLDER->populate_map(1);
load_object( HOLDER );
if(find_object(HOLDER)) {
destruct(find_object(HOLDER));
}
}
call_out("report", 1);
reclaim_objects();
return 1;
}
If we start a fresh boot of the testsuite we can make the reserved memory increase arbitrarily fast using this method. It is also easy to do via eval if you want to change N:
eval return explode( mud_status(0) , "\n" )[<2..<1]
eval for( int i = 0 ; i < N ; i++ ) destruct( load_object( "/clone/memory_holder" ) );reclaim_objects();
The amount gained is fairly consistently within the range of [500,1000]*N bytes for us.
I would also highlight that at no time during this does check_memory return any leaks or mismatched reference numbers.
On a side note it seems that it is possible to maybe roll the memory_info() integer? On a fresh boot of the testsuite:
> eval for( int i = 0 ; i < 7000 ; i++ ) {object ob = load_object( "/clone/memory_holder" );ob->populate_map(1);destruct(ob);}
Result = 0
> eval return explode( mud_status(0) , "\n" )[<2..<1]
Result = ({ /* sizeof() == 2 */
"Total accounted: 18446744071646916586",
"Max RSS: 4380733440"
})
> eval return memory_info()
Result = -2062635551
FYI: I have not tried rolling without debug, debugmalloc, debugmalloc_extensions and package_develop compile options on.